PIPA
项目地址:https://github.com/ZJU-SPAIL/pipa
Pipa项目还在发展当中,详细请参阅开源项目地址。
PIPA (Progressive & Intelligent Performance Analytics) is a platform that aggregates a complete toolchain of performance data collection, processing, and analysis with advanced algorithms, enabling users to effortlessly obtain in – depth insights into the performance of their systems and applications. It bridges the gap between raw performance data and actionable information, allowing for quick identification of bottlenecks and optimization opportunities.
PIPA (枇杷, loquat) is a local fruit of Zhejiang, China. PIPA consists of three parts: loquat tree, flower and fruit, which represent the collecting & processing, analysis and conclusion of performance data respectively.
PIPA is still in the active development process, and the current development focus is on the loquat tree.
Features
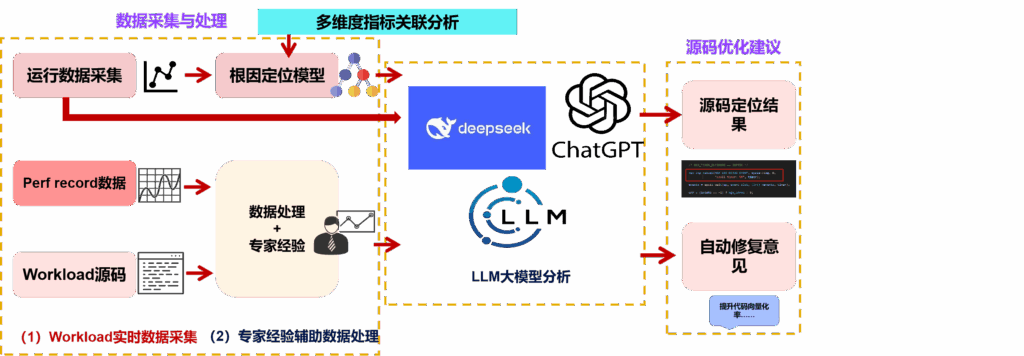
- Data Collecting: PIPA can collect data from a variety of sources, using tools like perf, sar, and more. It supports multiple platforms including x86_64, ARM, and RISC-V, making it versatile and adaptable. Currently PIPA is capable of collecting and parsing perf and sar data, providing detailed performance metrics.
- Script Generation: To reduce the noise generated by the Python runtime, PIPA can generate scripts that collect performance data.
- Data Processing: PIPA can process the collected performance data, including alignment and segmentation, to serve meaningful analysis.
- Data Visualization: PIPA can visualize based on the performance data collected to provide intuitive insights.
- Data Analytics: PIPA will integrate SPAIL’s performance methodology and models to provide meaningful analysis and reveal software and hardware bottlenecks.
Installation
PIPA can be easily installed using pip:
pip install PyPIPA
Quickstart
After installation, you can start using PIPA to collect, integrate, and analyze your data.
To generate a script that collect performance data, you only need to use:
pipa generate
Then you can complete the interaction through the CLI to provide the necessary parameters. You can choose to start the workload with perf, or you can choose to observe the system directly.
For the detailed case study, please refer to the quick-start.
PIPA’s API documentation is available at https://zju-spail.github.io/pipa/.
Build
To build PIPA, you can use the python command with the build module: python -m build, we use hatchling as the build backend.
LICENSE
PIPA is distributed under the terms of the MIT License.
Contributing
Contributions to PIPA are always welcome. Whether it’s feature enhancements, bug fixes, or documentation, your contributions are greatly appreciated.